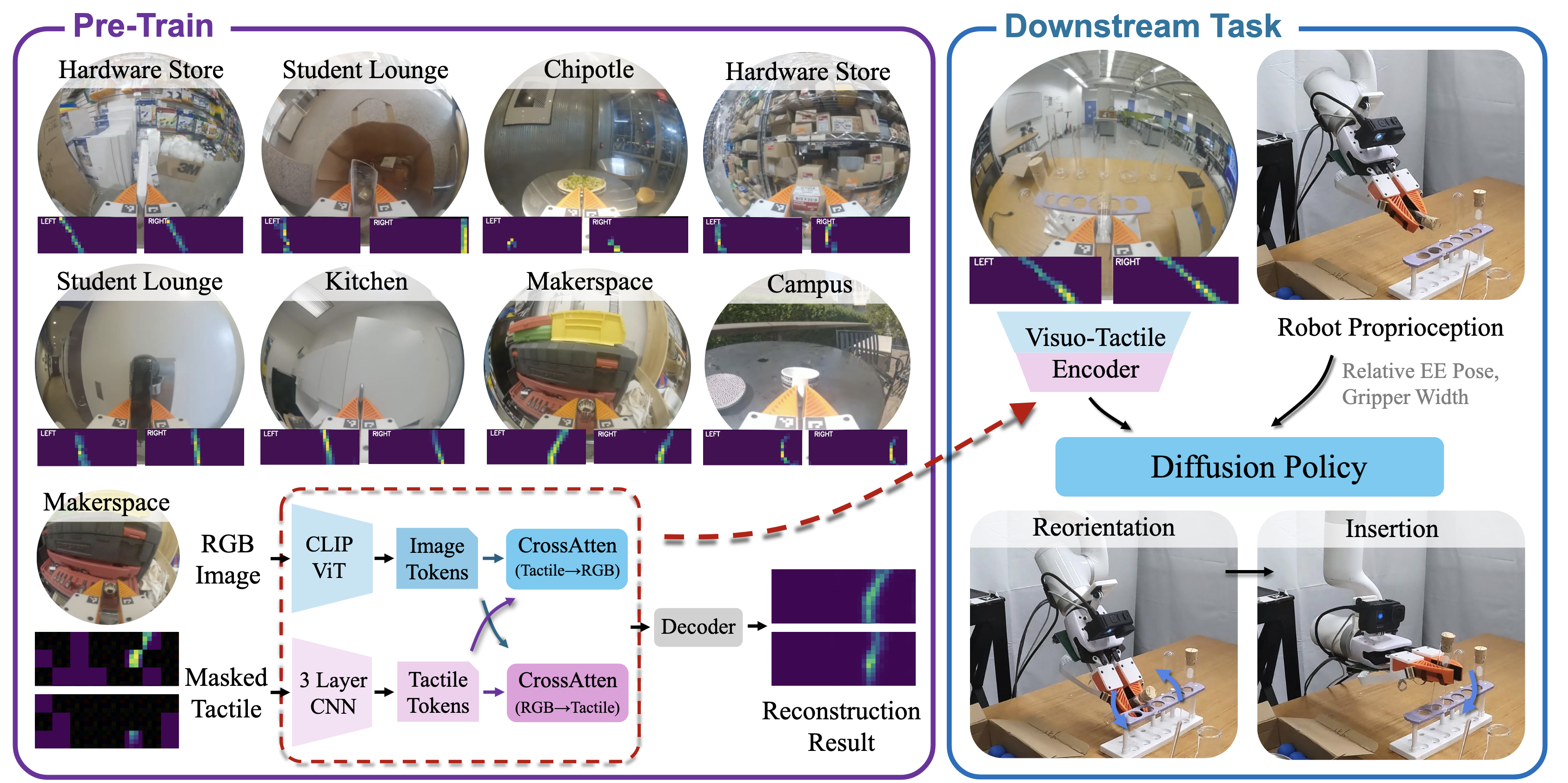
Visuo-Tactile Pretraining & Downstream Imitation Learning
We pretrain on a large corpus of image-tactile pairs using a cross-attention mechanism. The model learns to reconstruct tactile images conditioned on masked tactile inputs and associated camera images. This pretraining yields a joint visuo-tactile representation, which is then combined with robot proprioceptive states and used as input for downstream manipulation tasks.